If want to find a a non linear relationship between two arrays, and it’s hard to model it using simple functions such as polynomial or exponential. We can try some nonparametric way, and decision tree based regression is a fast and good way.
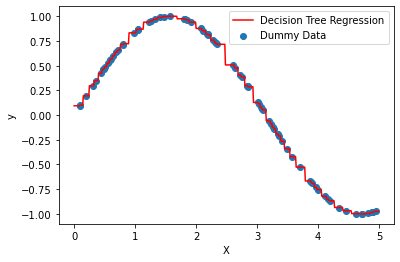
Case 1, where we don’t have too much outliers
import numpy as np import matplotlib.pyplot as plt from sklearn.tree import DecisionTreeRegressor
# Create sample dummy data np.random.seed(0) X = np.sort(5 * np.random.rand(80, 1), axis=0) y = np.sin(X).ravel()
# Fit the decision tree regressor tree = DecisionTreeRegressor() tree.fit(X, y)
# Visualize the dummy data and the model's predictions plt.figure() plt.scatter(X, y, label='Dummy Data') plt.plot(X_test, y_pred, color='red', label='Decision Tree Regression') plt.legend() plt.xlabel('X') plt.ylabel('y') plt.show()
where we don’t need to worry about over fit, and use the default depth values, and the results look like this:
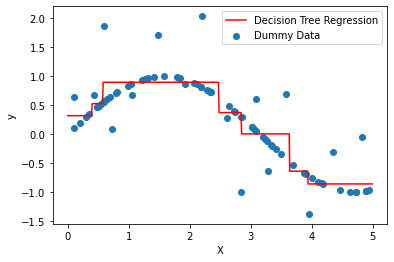
Case 2, where we have some outliers
import numpy as np import matplotlib.pyplot as plt from sklearn.tree import DecisionTreeRegressor
# Create sample dummy data np.random.seed(0) X = np.sort(5 * np.random.rand(80, 1), axis=0) y = np.sin(X).ravel()
y[::5] += 3 * (0.5 - np.random.rand(16)) # Add some noise to the data
# Fit the decision tree regressor tree = DecisionTreeRegressor(max_depth=3) tree.fit(X, y)
# Visualize the dummy data and the model's predictions plt.figure() plt.scatter(X, y, label='Dummy Data') plt.plot(X_test, y_pred, color='red', label='Decision Tree Regression') plt.legend() plt.xlabel('X') plt.ylabel('y') plt.show()
we we can reduce the depth of the decision tree, and avoid over fit, and results looks like this:
Reprint policy:
All articles in this blog are used except for special statements
CC BY 4.0
reprint policy. If reproduced, please indicate source
robot learner
!